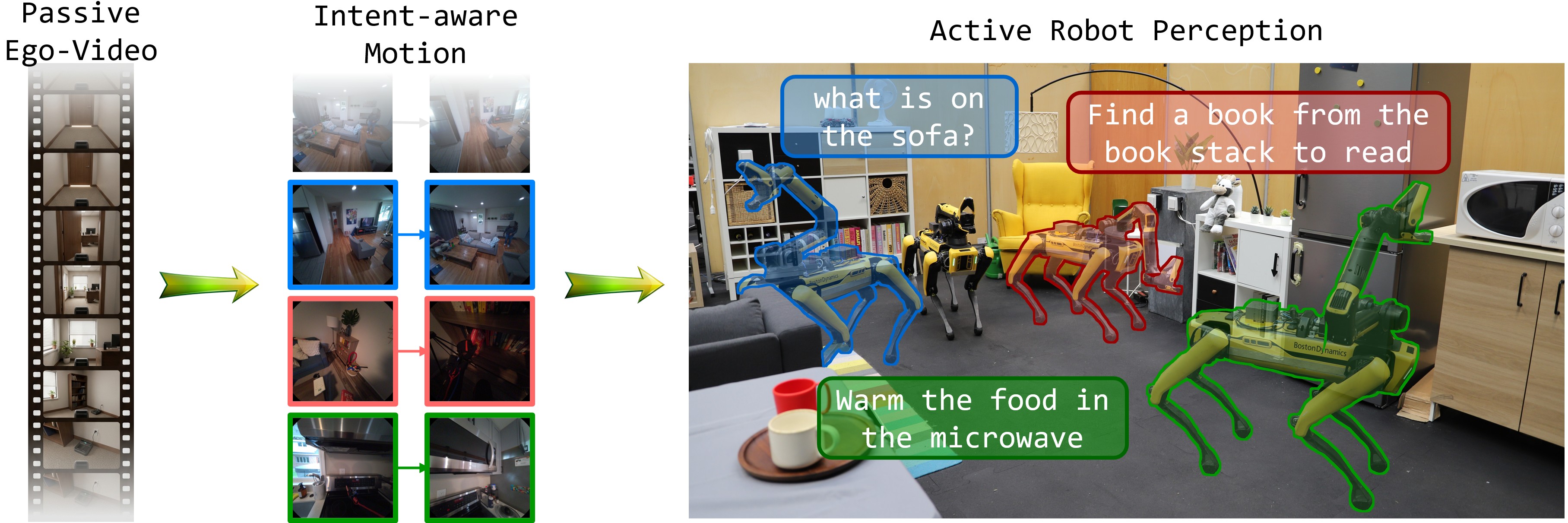
Autonomous robots often need to move their camera before they can act: to inspect an object, reveal an occluded region, or obtain a view that responds to a user's intent. While vision-language navigation translates instructions to base motion and vision-language-action policies map instructions to manipulation actions, language-conditioned camera motion remains comparatively underexplored as a first-class action. We formulate language-conditioned camera motion generation: given a current RGB observation and a free-form natural-language intent, predict a relative target camera pose for the next observation. This task is inherently non-trivial: viewpoint changes are driven by latent perceptual intentions, and a valid motion may operate at different semantic granularity, from entering a room to looking around a corner, inspecting a visible object, or revealing an occluded detail. To model this structure, we mine multi-intention camera-motion supervision from egocentric video, pairing plausible intents and observation-gain descriptions with relative SE(3) target poses. We propose LIME, a vision-language camera-motion generator that combines an auto-regressive observation-gain output with a continuous flow-matching pose head. This design lets the model jointly predict what the next view should reveal while representing multi-hypothesis target views. Across experiments and downstream robotic tasks, we show that LIME can learn to actively choose camera poses from passive human video, turning ordinary egocentric recordings into supervision for intent-aware active perception.
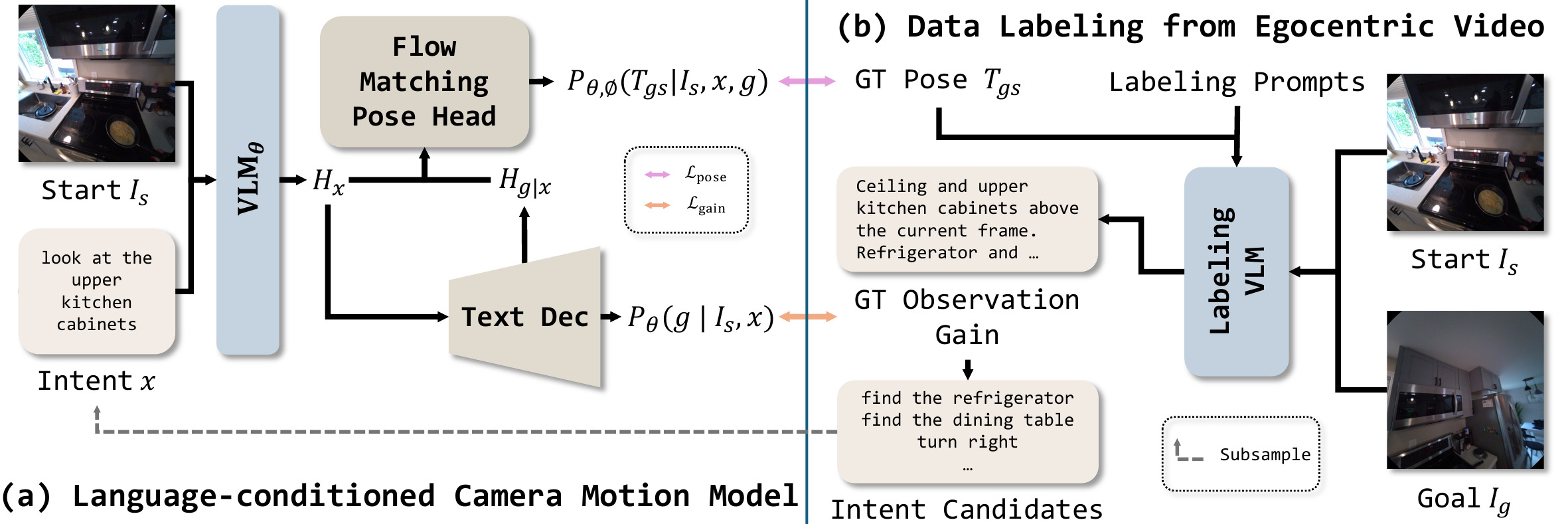
(a) LIME implements language-conditioned camera motion generation with two coupled interfaces over a shared vision-language representation. A language interface autoregressively generates an observation-gain description, a summary of what the next view should reveal beyond the current one, keeping part of the task in the VLM's native output space. A continuous flow-matching pose head then models the conditional distribution of relative SE(3) target poses from the fused representation, capturing the multiple valid viewpoints that can satisfy the same image-intent pair. (b) To obtain supervision without teleoperated demonstrations, we mine passive egocentric video: temporally separated frame pairs provide the relative camera transform, while a hindsight VLM labeller produces plausible intents and observation-gain descriptions. This yields roughly 3M intent-conditioned examples from RoomTour3D and Nymeria, spanning room-scale walkthroughs and body-scale egocentric interactions.
LIME runs on a real robot: given the current view and an intent, it predicts where to move the camera to acquire intent-relevant visual evidence. Use the thumbnails or arrows below to switch between examples.
LIME on ScanNet++: for each scene, the left image is the input view; given a free-form intent (buttons below), LIME predicts where the camera should move next, shown on the right. Use the scene selector to switch scenes. The camera frustums, colored with the viridis colormap, are N = 5 relative target poses sampled from LIME's continuous flow-matching pose head.
Input view
Intent
LIME gives a manipulation policy a better view before it acts. We deploy LIME on LIBERO-Goal with a randomly permuted initial robot pose, and compare two policies starting from the same randomized initial state: running the VLA policy directly (left clip), versus running LIME first and then the VLA policy (right clip). The blue border marks LIME's viewpoint change motion and the orange border marks the VLA policy. Across all 10 tasks, a single LIME viewpoint step before the same policy sharply improves the downstream manipulation success rate. Use the buttons to switch tasks.
26% → 74% overall LIBERO-Goal success rate — one LIME viewpoint step before the same manipulation policy
Real-world examples: LIME is run before manipulation with the intent corresponding to the manipulation goal, repositioning the camera to acquire the visual evidence needed to act, and again after manipulation with an intent to verify the manipulation result. The manipulation in these settings is performed by VidBot.
Multi-round setting: LIME runs iteratively over multiple rounds, supporting long-horizon tasks such as navigating toward and inspecting a distant target, or observing an object from different aspects (e.g., for scanning). *Videos are partially sped up.
LIME supports embodied question answering: instead of answering from a fixed view, the agent first moves its camera to acquire the visual evidence a question needs. We convert each question into a view-selection intent, let LIME predict where to look, and have a vision-language model answer from the resulting view. We evaluate this on AVS-ProcTHOR across existence, counting, and state questions, where LIME's predicted view exposes the relevant object or region needed to answer.
Initial view

View after LIME
@article{sun2026lime,
title={LIME: Learning Intent-aware Camera Motion from Egocentric Video},
author={Sun, Boyang and Li, Jiajie and Yang, Yung-Hsu and Zhang, Chenyangguang
and Engelbracht, Tim and Hong, Sunghwan and Cadena, Cesar
and Pollefeys, Marc and Blum, Hermann},
journal={arXiv preprint arXiv:2607.02417},
year={2026}
}